1, principi de transmissió de vídeo
El vídeo consisteix a utilitzar el principi de retenció de la visió de l'ull humà, mitjançant la reproducció d'una sèrie d'imatges, per fer que l'ull humà senti el moviment. El vídeo només es transmet i la quantitat de vídeo és molt gran, cosa que és inacceptable per a la xarxa i l’emmagatzematge existents. Per tal que el vídeo sigui fàcil de transmetre i emmagatzemar, la gent troba que el vídeo té molta informació repetida. Si la informació duplicada s'elimina de l'extrem de transmissió i es recupera a l'extrem receptor, el fitxer de dades de vídeo es redueix considerablement, de manera que hi ha disponible l'estàndard de compressió de vídeo H.264.
Les dades de la imatge original del vídeo es comprimiran en format de codificació H.264 i les dades de mostreig d’àudio es comprimiran en format de codificació AAC. Després de codificar i comprimir, el contingut de vídeo és realment propici per a l’emmagatzematge i la transmissió. No obstant això, quan es mira la reproducció, el procés de descodificació també és necessari en conseqüència. Per tant, és obvi que es necessita una mena de convenció tant per codificador com per descodificador entre codificació i descodificació. En termes de codificació i descodificació d’imatges de vídeo, aquest conveni és senzill:
El codificador codifica diverses imatges i produeix un GOP (grup d'imatges) en un segment. Quan es reprodueix, el descodificador llegeix una secció de GOP per descodificar-lo, després llegeix la imatge i, a continuació, mostra la pantalla. GOP (grup d'imatges) és una sèrie d'imatges contínues, que consta d'un fotograma I i diversos fotogrames B / P. És la unitat bàsica de l'accés del codificador i descodificador d'imatges de vídeo. La seqüència de disposició es repetirà fins al final de la imatge. El fotograma I és un marc de codificació intern (també conegut com fotograma clau), el fotograma P és un marc de predicció directa (fotograma de referència directa) i el fotograma B és un marc d’interpolació bidireccional (fotograma de referència bidireccional). En resum, el fotograma I és una imatge completa, mentre que el registre P i B canvia en relació amb el fotograma I. Sense els fotogrames I, no es poden descodificar els fotogrames P i B.
A l’estàndard de compressió H.264, s’utilitzen fotogrames I, fotogrames P i fotogrames B per representar la imatge de vídeo transmesa.
Tornar al principi
2 、 Frame I, P, frame B, GOP
Marc I
Quadre I: és a dir, imatge intra codificada. El marc I representa el marc clau i podeu entendre que la imatge d’aquest marc es conserva completament; per descodificar només cal completar les dades del marc (perquè conté la imatge completa). També conegut com a imatge interna, el fotograma I sol ser el primer fotograma de cada GOP (una tecnologia de compressió de vídeo utilitzada per MPEG). Després d'una compressió moderada, es pot utilitzar com a punt de referència d'accés aleatori i es pot considerar com una imatge. En la codificació MPEG, algunes seqüències de fotogrames de vídeo es comprimeixen en fotogrames I; alguns es comprimeixen en fotogrames P; i alguns es comprimeixen en fotogrames B. El mètode I frame és un mètode de compressió de fotogrames, també conegut com a mètode de compressió "fotograma clau". El mètode I frame és una tecnologia de compressió basada en DCT (transformada de cosinus discret), que és similar a l'algorisme de compressió JPEG. La relació de compressió de 1/6 es pot aconseguir utilitzant la compressió de fotogrames I sense traça de compressió evident.
[Emmarco funcions]
1. és un marc de codificació per compressió de fotogrames complets. Codifica i transmet tota la informació de la imatge del marc mitjançant compressió JPEG;
2. la imatge completa només es pot reconstruir utilitzant les dades del fotograma I durant la descodificació;
3. el marc I descriu el fons de la imatge i els detalls del cos en moviment;
4. El marc I no es genera referint-se a altres imatges;
5. El fotograma I és el marc de referència del fotograma P i del fotograma B (la seva qualitat afecta directament la qualitat de cada fotograma del mateix grup);
6. El fotograma I és el fotograma bàsic (el primer fotograma) del grup de fotogrames GOP i només hi ha un fotograma I en un grup;
7. El vector de moviment no és necessari per al fotograma I;
8. la informació del marc I és relativament gran.
[Procés de codificació de marcs]
(1) La predicció intra es realitza per determinar el mode de predicció intra.
(2) El valor del píxel resta el valor predit per obtenir el residu.
(3) El residu es transforma i quantifica.
(4) Codificació de longitud variable i codificació aritmètica.
(5) La imatge es reconstrueix i filtra i la imatge s'utilitza com a marc de referència d'altres marcs.
Per exemple, en el sistema de videoconferència, la imatge que envia el terminal a MCU (o MCU al terminal) no envia una imatge completa a l'extrem remot alhora, sinó només la part que canvia després d'enviar la imatge en funció de l'anterior imatge. Si l'estat de la xarxa no és bo, el terminal rebrà l'extrem remot o s'enviarà a la imatge remota amb pèrdua de paquets i la imatge es bloquejarà. En aquest cas, si no hi ha cap mecanisme d’enquadrament per enviar una nova imatge completa al local (o local tornar a enviar una nova imatge completa al comandament a distància), es mostrarà la pantalla floral de la imatge de sortida del terminal. El fenomen de Caton esdevindrà cada cop més greu, cosa que farà que la reunió no es dugui a terme amb normalitat.
En el procés de reproducció de la pantalla de vídeo, si es perd el fotograma I, també apareixerà el fotograma P que apareix tan aviat com no es pugui resoldre i apareixerà el fenomen de la pantalla negra; si es perd el fotograma P, la pantalla de vídeo mostrarà el fenomen de la pantalla de flors i el mosaic.
En el sistema de videoconferència, el marc I només es produirà dins del límit d’amplada de banda de la reunió i no superarà l’amplada de banda de la reunió i entrarà en vigor. El mecanisme d’enquadrament I no només existeix a l’MCU, sinó també al servidor de paret de TV i al servidor de vídeo. Es tracta de resoldre el problema de la pèrdua de paquets en cas de males condicions de xarxa, com ara la pantalla i el botó de la imatge, que afectaran el progrés normal de la reunió.
Marc P
Marc P: és a dir, imatge codificada predictiva. El marc P representa la diferència entre aquest marc i el marc clau anterior (o marc P). En descodificar, la diferència definida en aquest marc s'ha de superposar a la imatge anterior emmagatzemada a la memòria cau per generar la imatge final. (és a dir, marc diferencial, el marc P no té dades d'imatge completes, només dades diferents del marc anterior)
[predicció i reconstrucció del marc P]
El fotograma P és un marc de referència I, en el qual el valor de predicció i el vector de moviment de "un punt" del fotograma P es troben al fotograma I, i la diferència de predicció i el vector de moviment es transmeten junts. El valor predit de "punt" del fotograma P es troba a partir del fotograma I segons el vector de moviment al receptor i s'afegeix la diferència per obtenir el valor de mostra del "punt" del fotograma P, de manera que es pot obtenir el fotograma P complet obtingut.
[Funcions del marc P]
1. El marc P és el marc de codificació amb 1-2 marcs darrere del marc I;
2. El fotograma P adopta un mètode de compensació de moviment per transmetre la diferència i el vector de moviment (error de predicció) entre el fotograma P i el fotograma I;
3. el valor de predicció i l'error de predicció al fotograma I s'han de resumir en la descodificació abans de reconstruir la imatge del fotograma P completa;
4. El marc P pertany a la codificació entre marcs de predicció directa. Només es refereix al fotograma I o fotograma P més proper a ell per davant;
5. El marc P pot ser el marc de referència del marc P després d’ell, o pot ser el marc de referència del marc B abans i després d’ell;
6. com que el marc P és un marc de referència, pot provocar la propagació d'un error de descodificació;
7. a causa de la transmissió de diferències, la compressió del quadre P és relativament alta.
Marc B
Quadre B: és a dir, imatge predita bidireccionalment. El marc B és un marc de diferència de dues vies, és a dir, la diferència entre el marc i els marcs frontal i posterior es registra en el marc B. En altres paraules, per descodificar el fotograma B, no només es necessita la imatge de memòria cau anterior, sinó també la imatge descodificada. La imatge final s’obté mitjançant la superposició de les imatges davantera i posterior i les dades del marc. La velocitat de compressió de fotogrames B és elevada, però la CPU estarà més cansada en descodificar.
[predicció i reconstrucció del marc B]
El quadre B es basa en el marc I o P frontal i el marc P a la part posterior com a marc de referència. Es troba el valor de predicció i dos vectors de moviment de "un punt" del quadre B, i es pren la diferència de predicció i el vector de moviment per transmetre. El receptor "esbrina (calcula)" el valor predit en dos fotogrames de referència segons el vector de moviment i resumeix amb diferència, i obté el valor de mostra de "cert punt" del fotograma B, obtenint així un fotograma B complet. Codificació de predicció bidireccional entre fotogrames per predicció de moviment
[Funcions del marc B]
1. El fotograma B és predit pel fotograma I frontal o P i el fotograma P posterior;
2. El fotograma B transmet l'error de predicció i el vector de moviment entre ell i el fotograma I o fotograma P i el fotograma P a la part posterior;
3. El marc B és un marc de codificació de predicció bidireccional;
4. La relació de compressió del quadre B és la més alta, perquè només reflecteix el canvi del cos principal del moviment entre els marcs de referència C i la predicció és més precisa;
5. El marc B no és un marc de referència i no provocarà la propagació d'un error de descodificació
[per què es necessita un marc B]
Per l’anterior, sabem que l’algoritme de descodificació de I i P és relativament senzill i que l’ocupació dels recursos és relativament petita. Només necessito completar-ho jo mateix. P. només necessita el descodificador per emmagatzemar en memòria cau la imatge anterior. Quan us trobeu amb P, és millor utilitzar la imatge emmagatzemada anteriorment. Si el flux de vídeo només té I i P, el descodificador pot llegir i descodificar mentre es llegeix i avança linealment. Per a nosaltres és molt còmode avançar, no m’agrada. Per què voleu introduir el marc B?
Moltes pel·lícules de la xarxa adopten un fotograma B, perquè la diferència entre fotogrames davanters i posteriors enregistrats pel fotograma B pot estalviar més espai que el fotograma P. Tot i això, el fitxer és petit i el descodificador té problemes. En la descodificació, no només s’utilitza la imatge emmagatzemada a la memòria cau, sinó també la següent imatge I o P (és a dir, pre-lectura i descodificació). A més, el fotograma B no es pot perdre simplement, ja que el fotograma B conté informació sobre la imatge, si simplement es perd i es repeteix amb la imatge anterior, provocarà la targeta d'imatge (de fet, es perd). Per tal d’estalviar espai, les pel·lícules de la xarxa solen utilitzar bastants fotogrames B. Com més s’utilitzen fotogrames B, causarà més problemes als jugadors que no admetin fotogrames B i més la imatge quedarà atrapada.
GOP (seqüència) i IDR
A h264, la imatge s’organitza en seqüència i una seqüència és un flux de dades després de codificar la imatge.
La primera imatge d’una seqüència s’anomena imatge IDR (actualitzeu la imatge immediatament) i la imatge IDR és una imatge fotograma I. H. 264 introdueix la imatge IDR per resincronitzar la descodificació. Quan el descodificador descodifica la imatge IDR, es buidarà immediatament la cua del marc de referència, sortirà o descartarà totes les dades descodificades, tornarà a buscar el conjunt de paràmetres i iniciarà una nova seqüència. D'aquesta manera, si hi ha un error important a la seqüència anterior, podeu obtenir l'oportunitat de tornar a sincronitzar aquí. Les imatges després de les imatges IDR mai es descodificaran mitjançant dades de les imatges IDR anteriors.
Una seqüència és una sèrie de fluxos de dades generats després de la codificació d'imatges amb poca diferència de contingut. Quan el moviment canvia menys, una seqüència pot ser molt llarga, perquè menys canvis de moviment representen que el canvi de contingut de la imatge de la imatge és molt petit, de manera que podeu fer un fotograma I i, després, sempre fotograma P i fotograma B. Quan el moviment canvia molt, una seqüència pot ser més curta, per exemple, conté un fotograma I i 3 o 4 fotogrames P.
En la seqüència de codificació de vídeo, GOP és un grup d'imatges, que fa referència a la distància entre dos fotogrames I i la referència es refereix a la distància entre dos fotogrames P. Es forma un grup d'imatges entre els dos fotogrames I, és a dir, GOP (grup d'imatges).



|
|
|
|
A quina distància (llarg) de la coberta del transmissor?
L'abast de transmissió depèn de molts factors. La distància real es basa en la instal·lació de l'antena d'altura, guany d'antena, utilitzant com a mitjà de construcció i altres obstruccions, la sensibilitat del receptor, l'antena del receptor. La instal·lació de l'antena més alta i l'ús en el camp, la distància serà molt més lluny.
Transmissor FM 5W exemple, l'ús a la ciutat i la ciutat natal:
Tinc un client d'ús del transmissor FM amb antena 5W EUA GP a la seva ciutat natal, i ho prova amb un cotxe, és cobrir 10km (6.21mile).
Puc provar el transmissor de FM amb antena GP 5W a la meva ciutat natal, que cobreixen al voltant 2km (1.24mile).
Puc provar el transmissor de FM amb antena 5W metge de capçalera a la ciutat de Guangzhou, que només cobreixen al voltant 300meter (984ft).
A continuació es presenten l'interval aproximat de diferents transmissors de FM de potència. (El rang és de diàmetre)
Transmissor FM 0.1W ~ 5W: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
Transmissor FM 15W ~ 80W: 3KM ~ 10KM
Transmissor FM 80W ~ 500W: 10KM ~ 30KM
Transmissor FM 500W ~ 1000W: 30KM ~ 50KM
Transmissor FM 1KW ~ 2KW: 50KM ~ 100KM
Transmissor FM 2KW ~ 5KW: 100KM ~ 150KM
Transmissor FM 5KW ~ 10KW: 150KM ~ 200KM
Com posar-se en contacte amb nosaltres per al transmissor?
Llámame + O 8618078869184
vam enviar un correu electrònic [protegit per correu electrònic]
1.How fins on vol cobrir de diàmetre?
2.How alta que la torre?
3.Where ets?
I li donarem un assessorament més professional.
Sobre Nosaltres
FMUSER.ORG és una empresa d’integració de sistemes centrada en equips de transmissió i transmissió de vídeo sense fil de radiofreqüència / estudi i processament de dades. Oferim tot, des de l'assessorament i la consultoria a través de la integració de bastidors fins a la instal·lació, la posada en servei i la formació.
Oferim transmissor FM, transmissor de televisió analògica, transmissor de televisió digital, transmissor UHF VHF, antenes, connectors de cable coaxial, STL, processament aeri, productes de difusió per a estudi, monitorització de senyals RF, codificadors RDS, processadors d’àudio i unitats de control de llocs remots, Productes IPTV, codificador / decodificador d’àudio / vídeo, dissenyats per satisfer les necessitats de grans xarxes de difusió internacionals i de petites estacions privades.
La nostra solució compta amb estació de ràdio FM / estació de televisió analògica / estació de televisió digital / equip d’estudi d’àudio i vídeo / enllaç de transmissor d’estudi / sistema de telemetría de transmissor / sistema de televisió d’hotel / transmissió en directe IPTV / transmissió en directe de transmissió / conferència de vídeo / sistema de difusió CATV.
Utilitzem productes de tecnologia avançada per a tots els sistemes, ja que sabem que l’alta fiabilitat i l’alt rendiment són tan importants per al sistema i la solució. Al mateix temps, hem d'assegurar-nos que el nostre sistema de productes té un preu molt raonable.
Tenim clients de radiodifusors públics i comercials, operadors de telecomunicacions i autoritats reguladores, i també oferim solucions i productes a molts centenars d’emissores locals, petites i comunitàries.
FMUSER.ORG porta exportant més de 15 anys i té clients a tot el món. Amb 13 anys d’experiència en aquest camp, comptem amb un equip professional per resoldre tot tipus de problemes del client. Ens dediquem a subministrar els preus extremadament raonables de productes i serveis professionals. Correu electrònic de contacte : [protegit per correu electrònic]
la nostra fàbrica

Tenim modernització de la fàbrica. Que són benvinguts a visitar la nostra fàbrica quan s'arriba a la Xina.

En l'actualitat, ja hi ha clients 1095 a tot el món van visitar la nostra oficina Guangzhou Tianhe. Si vostè ve a la Xina, que són benvinguts a visitar-nos.
a la Fira

Aquesta és la nostra participació en 2012 Global Sources Hong Kong Electronics Fair . Els clients de tot el món finalment tenir l'oportunitat de reunir-se.
On és Fmuser?
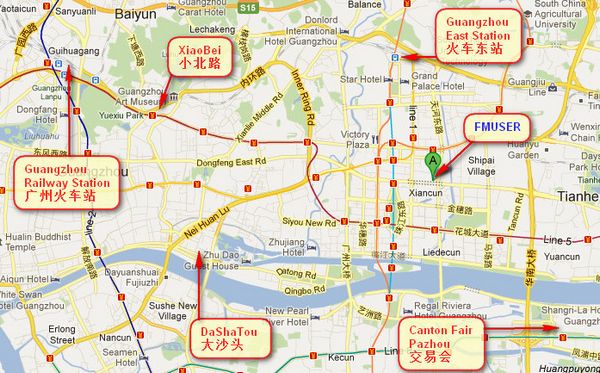
Podeu cercar aquests números " 23.127460034623816,113.33224654197693 "a google map, podreu trobar la nostra oficina fmuser.
FMUSER oficina de Guangzhou es troba al districte de Tianhe, que és el centre del Cantó . molt a prop fins al Fira de Canton , Estació de tren de Guangzhou, Xiaobei carretera i Dashatou , Només cal 10 minuts si pren TAXI . Benvinguts amics de tot el món a visitar i negociar.
Contacte: Blue Sky
Cel·lular: + 8618078869184
WhatsApp: + 8618078869184
Wechat: + 8618078869184
Adreça electrònica: [protegit per correu electrònic]
QQ: 727926717
Skype: sky198710021
Adreça: Sala de No.305 Huilan Edifici No.273 Huanpu carretera Guangzhou, Xina Codi postal: 510620
|
|
|
|
Anglès: Acceptem tots els pagaments, com PayPal, targeta de crèdit, Western Union, Alipay, Money Bookers, T / T, LC, DP, DA, OA, Payoneer, si teniu cap pregunta, poseu-vos en contacte amb mi [protegit per correu electrònic] o WhatsApp + 8618078869184
-
PayPal.  www.paypal.com www.paypal.com
Recomanem que utilitzi PayPal per comprar els nostres articles, el PayPal és una forma segura per comprar a Internet.
Cada pàgina de la nostra llista d'elements de fons a la part superior tenen un logotip de PayPal per pagar.
Targeta de crèdit.Si no té PayPal, però vostè ha targeta de crèdit, també pot fer clic al botó groc de PayPal per pagar amb la targeta de crèdit.
-------------------------------------------------- -------------------
Però si vostè no té una targeta de crèdit i no tenir un compte de PayPal o difícil va aconseguir un accout PayPal, pot utilitzar el següent:
Unió Occidental.  www.westernunion.com www.westernunion.com
Pagar per Western Union a mi:
Nom i cognoms: Yingfeng
Cognom / Cognom / Nom de família: Zhang
Nom complet: Yingfeng Zhang
País: Xina
Ciutat: Guangzhou
|
-------------------------------------------------- -------------------
T / T. pagar amb T / T (transferència bancària / transferència telegràfica / transferència bancària)
Primera informació bancària (COMPTE DE L'EMPRESA):
SWIFT BIC: BKCHHKHHXXX
Nom del banc: BANK OF CHINA (HONG KONG) LIMITED, HONG KONG
Adreça bancària: BANC DE LA TORRE DE XINA, 1 GARDEN ROAD, CENTRAL, HONG KONG
CÓDIG BANC: 012
Nom del compte: FMUSER INTERNATIONAL GROUP LIMITED
Núm de compte. : 012-676-2-007855-0
-------------------------------------------------- -------------------
Segona informació bancària (COMPTE DE L'EMPRESA):
Beneficiari: Fmuser International Group Inc.
Número de compte: 44050158090900000337
Banc del beneficiari: sucursal del Guangdong de China Construction Bank
Codi SWIFT: PCBCCNBJGDX
Adreça: carretera NO.553 Tianhe, Guangzhou, Guangdong, districte de Tianhe, Xina
** Nota: quan transferiu diners al nostre compte bancari, NO escriviu res a l'àrea de comentaris, en cas contrari no podrem rebre el pagament a causa de la política governamental sobre comerç internacional.
|
|
|
|
* Aquest document s'enviarà a 1 2-dies de treball quan el pagament és clar.
* Enviarem a la seva adreça de PayPal. Si vostè vol canviar la direcció, si us plau, envieu la vostra direcció correcta i número de telèfon a la vostra adreça [protegit per correu electrònic]
* Si els paquets es troba per sota 2kg, ens enviaran a través de correu aeri, trigarà aproximadament 15-25days a la mà.
Si el paquet és més que 2kg, enviarem a través d'EMS, DHL, UPS, Fedex lliurament ràpid expressa, prendrà al voltant de 7 ~ 15days al seu costat.
Si el paquet de més de 100kg, anem a enviar per DHL o el noli aeri. Es durà a prop 3 ~ 7days al seu costat.
Tots els paquets són la forma xinesa de Guangzhou.
* El paquet s'enviarà com a "regal" i es descomptarà el mínim possible, perquè el comprador no hagi de pagar l'impost.
* Després de la nau, li enviarem un correu electrònic i li donarà el nombre de seguiment.
|
|
|
Per a la garantia.
Poseu-vos en contacte amb nosaltres --- >> Envieu-nos l'article --- >> Rebeu i envieu un altre substitut.
Nom: Liu xiaoxia
Direcció: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou, Xina.
Postal: 510620
Telèfon: + 8618078869184
Si us plau, torni a aquesta adreça i escriure el seu PayPal, nom, adreça problema a la nota: |
|
El nostre altre producte:













