(1) Informació redundant del senyal de vídeo
Prenent com a exemple el format de component YUV d’enregistrament de vídeo digital, YUV representa brillantor i dos senyals de diferència de color respectivament. Per exemple, per al sistema de televisió pal existent, la freqüència de mostreig del senyal de luminància és de 13.5 MHz; la banda de freqüència del senyal de croma sol ser la meitat o menys del senyal de brillantor, que és de 6.75 MHz o 3.375 MHz. Prenent com a exemple la freqüència de mostreig de 4: 2: 2, el senyal Y adopta 13.5 mhz, els senyals de croma U i V es mostren a 6.75 mhz i el senyal de mostreig es quantifica en 8 bits, llavors es pot calcular la velocitat de codi del vídeo digital com segueix:
13.5 * 8 + 6.75 * 8 + 6.75 * 8 = 216Mbit / s
Si una quantitat tan gran de dades s’emmagatzema o es transmet directament, serà difícil utilitzar la tecnologia de compressió per reduir la velocitat de bits. El senyal de vídeo digital es pot comprimir segons dues condicions bàsiques:
L. redundància de dades. Per exemple, redundància espacial, redundància de temps, redundància d’estructura, redundància d’entropia d’informació, etc., és a dir, hi ha una forta correlació entre els píxels de la imatge. L’eliminació d’aquesta redundància no comporta pèrdua d’informació, i és una compressió sense pèrdues.
L. redundància visual. Algunes característiques dels ulls humans, com el llindar de discriminació de la brillantor, el llindar visual, són diferents en sensibilitat a la brillantor i al croma, cosa que fa impossible introduir errors adequats en la codificació i no es detectaran. Les característiques visuals dels ulls humans es poden utilitzar per intercanviar per compressió de dades amb certa distorsió objectiva. Aquesta compressió té pèrdues.
La compressió del senyal de vídeo digital es basa en les dues condicions anteriors, cosa que fa que les dades de vídeo es comprimeixin molt, cosa que propicia la transmissió i l’emmagatzematge. Els mètodes habituals de compressió de vídeo digital són la codificació mixta, que consisteix a combinar la codificació de transformades, l'estimació del moviment i la compensació del moviment, i la codificació d'entropia per comprimir la codificació. Normalment, la codificació per transformació s’utilitza per eliminar la redundància intraquadre de la imatge, i l’estimació del moviment i la compensació del moviment s’utilitzen per eliminar la redundància entre fotogrames de la imatge i la codificació per entropia s’utilitza per millorar encara més l’eficiència de compressió. Es presenten breument els tres mètodes de codificació per compressió següents.
(a) Mètode de codificació per compressió
(b) Transformar la codificació
La funció de la codificació de transformació és transformar el senyal d’imatge descrit en el domini espacial en el domini de freqüència i després codificar els coeficients transformats. En termes generals, la imatge té una forta correlació a l’espai i la transformació en domini de freqüència pot produir descorrelació i concentració d’energia. La transformada ortogonal comuna inclou transformada de Fourier discreta, transformada de cosinus discreta, etc. La transformació de cosinus discreta s’utilitza àmpliament en la compressió de vídeo digital.
La transformada discreta del cosinus es denomina transformada DCT. Pot transformar el bloc d’imatges de L * l de domini espacial a domini de freqüència. Per tant, en el procés de compressió i codificació d’imatges basat en DCT, la imatge s’ha de dividir en blocs d’imatges no superposats. Suposem que la mida d’una imatge és de 1280 * 720, que es divideix en blocs d’imatges de 160 * 90 amb una mida de 8 * 8 sense superposar-se en forma de quadrícula. A continuació, es pot realitzar la transformació DCT per a cada bloc d’imatges.
Després de dividir el bloc, cada bloc d’imatges de 8 * 8 punts s’envia al codificador DCT i el bloc d’imatges de 8 * 8 es transforma del domini espacial al domini de freqüència. La figura següent mostra un exemple d’un bloc d’imatges de 8 * 8 en què el número representa el valor de brillantor de cada píxel. Es pot veure per la figura que els valors de brillantor de cada píxel d’aquest bloc d’imatges són relativament uniformes, sobretot el valor de brillantor dels píxels adjacents no és molt gran, cosa que indica que el senyal de la imatge té una forta correlació.
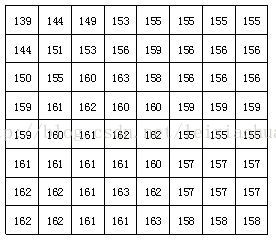
Un bloc real d’imatges de 8 * 8
La figura següent mostra els resultats de la transformació DCT del bloc d’imatges a la figura anterior. Es pot veure per la figura que, després de la transformació del DCT, el coeficient de baixa freqüència a l’angle superior esquerre concentra molta energia, mentre que l’energia del coeficient d’alta freqüència a l’angle inferior dret és molt petita.
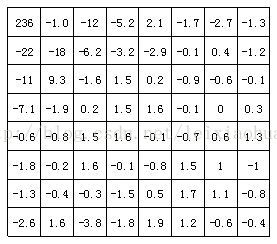
Els coeficients del bloc d’imatges després de la transformació DCT
El senyal s’ha de quantificar després de la transformació DCT. Com que els ulls humans són sensibles a les característiques de baixa freqüència de les imatges, com ara la brillantor general dels objectes, i no als detalls d’alta freqüència de la imatge, de manera que, en el procés de transmissió, la informació d’alta freqüència es pot transmetre menys o menys, només la part de baixa freqüència. El procés de quantificació redueix la transmissió d'informació quantificant els coeficients de la regió de baixa freqüència i la quantització aproximada dels coeficients a la regió d'alta freqüència, la qual cosa elimina la informació d'alta freqüència que no és sensible als ulls humans. Per tant, la quantització és un procés de compressió amb pèrdues i el principal motiu del dany de qualitat en la codificació de compressió de vídeo.
El procés de quantificació es pot expressar mitjançant la següent fórmula:

Entre ells, FQ (U, V) representa el coeficient DCT després de la quantificació; f (U, V) representa el coeficient DCT abans de la quantització; Q (U, V) representa la matriu de ponderació de quantització; q és el pas de quantització; round fa referència a la consolidació i es pren el valor a produir com el valor enter més proper.
Seleccioneu el coeficient de quantificació de manera raonable i el resultat després de quantificar el bloc d’imatges transformat es mostra a la figura.

Coeficient DCT després de la quantificació
La majoria dels coeficients DCT es canvien a 0 després de la quantització, mentre que només uns quants coeficients són valors diferents de zero. En aquest moment, només cal comprimir i codificar aquests valors diferents de zero.
(b) Codificació d’entropia
La codificació d’entropia s’anomena perquè la longitud mitjana del codi després de la codificació s’acosta al valor d’entropia de la font. La codificació d’entropia s’implementa mitjançant VLC (codificació de longitud variable). El principi bàsic és donar codi curt al símbol amb alta probabilitat a la font, i donar codi llarg al símbol amb una probabilitat petita d’aparició, per tal d’obtenir estadísticament la longitud mitjana del codi més curta. La codificació de longitud variable sol incloure codi Hoffman, codi aritmètic, codi d'execució, etc. La codificació de longitud d'execució és un mètode de compressió molt senzill, la seva eficiència de compressió no és alta, però la velocitat de codificació i descodificació és ràpida i encara es fa servir àmpliament, especialment després de la transformació de la codificació, fent servir la codificació de longitud de cursa, té un bon efecte.
En primer lloc, el coeficient de CA immediatament posterior al coeficient de CC de sortida del quantitzador s’escanejarà en tipus Z (com es mostra a la línia de fletxa). L’exploració en Z transforma el coeficient de quantització bidimensional en una seqüència unidimensional i, a continuació, continua amb la codificació de la longitud del recorregut. Finalment, s’utilitza un altre codi de longitud variable per codificar les dades després de la codificació d’execució, com ara la codificació Hoffman. Mitjançant aquest tipus de codificació de longitud variable, es millora encara més l’eficiència de la codificació.
(c) Estimació del moviment i compensació del moviment
L’estimació del moviment i la compensació del moviment són mètodes eficaços per eliminar la correlació de la direcció temporal de les seqüències d’imatges. Els mètodes de transformació, quantització i codificació de l'entropia DCT descrits anteriorment es basen en una imatge de fotograma. Mitjançant aquests mètodes, es pot eliminar la correlació espacial entre píxels de la imatge. De fet, a més de la correlació espacial, el senyal d’imatge té correlació temporal. Per exemple, per al vídeo digital amb fons estàtic, com ara la difusió de notícies i el petit moviment del cos principal de la imatge, la diferència entre cada imatge és molt petita i la correlació entre imatges és molt gran. En aquest cas, no necessitem codificar cada imatge de fotogrames per separat, sinó que només podem codificar les parts modificades dels fotogrames de vídeo adjacents, per reduir encara més la quantitat de dades. Aquest treball es realitza mitjançant l'estimació del moviment i la compensació del moviment.
La tecnologia d’estimació del moviment generalment divideix la imatge d’entrada actual en diversos subblocs d’imatges petites que no es superposen, per exemple, la mida d’una imatge de marc és de 1280 * 720. En primer lloc, es divideix en blocs d’imatges de 40 * 45 amb 16 * 16 mida que no es superposen en forma de quadrícula i, a continuació, dins l’abast d’una finestra de cerca de la imatge anterior o de la darrera imatge, trobeu un bloc per a cada bloc d’imatges per trobar un bloc d’imatges dins de l’àmbit d’un finestra de cerca El bloc d'imatges més semblant. El procés de cerca s’anomena estimació del moviment. En calcular la informació de posició entre el bloc d’imatges més similar i el bloc d’imatges, es pot obtenir un vector de moviment. D’aquesta manera, es pot restar el bloc d’imatges actual del bloc d’imatges més semblant apuntat pel vector de moviment de la imatge de referència i es pot obtenir un bloc d’imatges residuals. Com que el valor de cada píxel del bloc d’imatges residuals és molt petit, es pot obtenir una relació de compressió més alta en la codificació de compressió. Aquest procés de resta s’anomena compensació del moviment.
Com que cal utilitzar una imatge de referència per a l'estimació del moviment i la compensació del moviment en el procés de codificació, és molt important seleccionar la imatge de referència. Generalment, el codificador divideix cada imatge d’imatges de fotogrames en tres tipus diferents segons les diferents imatges de referència: fotograma I (intra), fotograma B (predicció de guia) i fotograma P (predicció). Com es mostra a la figura.
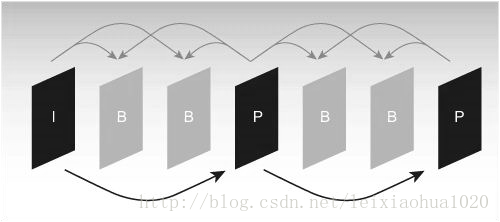
Seqüència típica d’estructura de fotogrames I, B, P
Com es mostra a la figura, el fotograma I només utilitza les dades del fotograma per codificar i no necessita estimació de moviment ni compensació del moviment durant el procés de codificació. Viouslybviament, com que el marc no elimina la correlació de la direcció del temps, la relació de compressió és relativament baixa. En el procés de codificació, el fotograma P utilitza un fotograma I frontal o fotograma P com a imatge de referència per a la compensació del moviment, de fet, codifica la diferència entre la imatge actual i la imatge de referència. El mode de codificació del fotograma B és similar al fotograma P, l’única diferència és que necessita utilitzar un fotograma I frontal o fotograma P i un fotograma I posterior o fotograma P per predir durant el procés de codificació. Per tant, cada codificació de fotogrames P ha d’utilitzar una imatge de fotograma com a imatge de referència, mentre que el fotograma B necessita dos fotogrames com a referència. En canvi, el fotograma B té una relació de compressió més alta que el fotograma P.
(d) Codificació mixta
El document presenta diversos mètodes importants en compressió i codificació de vídeo. En aplicacions pràctiques, aquests mètodes no estan separats i solen combinar-se per aconseguir el millor efecte de compressió. La següent figura mostra el model de codificació híbrida (és a dir, codificació de transformació + estimació de moviment i compensació de moviment + codificació d’entropia). El model s’utilitza àmpliament a MPEG1, MPEG2, H.264 i altres estàndards. A partir de la figura, podem veure que la imatge d’entrada actual s’ha de dividir en blocs primer, el bloc de la imatge obtinguda pel bloc es restarà de la imatge prevista després de la compensació del moviment per obtenir la diferència d’imatge x, i després es realitzen transformacions i quantificacions de DCT per al bloc d’imatges de diferències. Les dades de sortida quantificades tenen dos llocs diferents: un és enviar-les al codificador d’entropia per codificar-les i el flux de codi codificat s’envia a una memòria cau Desa al dispositiu i espera la transmissió. Una altra aplicació és contrarestar quantificar i invertir el canvi al senyal x ', que afegeix la sortida del bloc d'imatges amb compensació de moviment per obtenir un nou senyal d'imatge de predicció i envia un nou bloc d'imatge de predicció a la memòria de trama.



|
|
|
|
A quina distància (llarg) de la coberta del transmissor?
L'abast de transmissió depèn de molts factors. La distància real es basa en la instal·lació de l'antena d'altura, guany d'antena, utilitzant com a mitjà de construcció i altres obstruccions, la sensibilitat del receptor, l'antena del receptor. La instal·lació de l'antena més alta i l'ús en el camp, la distància serà molt més lluny.
Transmissor FM 5W exemple, l'ús a la ciutat i la ciutat natal:
Tinc un client d'ús del transmissor FM amb antena 5W EUA GP a la seva ciutat natal, i ho prova amb un cotxe, és cobrir 10km (6.21mile).
Puc provar el transmissor de FM amb antena GP 5W a la meva ciutat natal, que cobreixen al voltant 2km (1.24mile).
Puc provar el transmissor de FM amb antena 5W metge de capçalera a la ciutat de Guangzhou, que només cobreixen al voltant 300meter (984ft).
A continuació es presenten l'interval aproximat de diferents transmissors de FM de potència. (El rang és de diàmetre)
Transmissor FM 0.1W ~ 5W: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
Transmissor FM 15W ~ 80W: 3KM ~ 10KM
Transmissor FM 80W ~ 500W: 10KM ~ 30KM
Transmissor FM 500W ~ 1000W: 30KM ~ 50KM
Transmissor FM 1KW ~ 2KW: 50KM ~ 100KM
Transmissor FM 2KW ~ 5KW: 100KM ~ 150KM
Transmissor FM 5KW ~ 10KW: 150KM ~ 200KM
Com posar-se en contacte amb nosaltres per al transmissor?
Llámame + O 8618078869184
vam enviar un correu electrònic [protegit per correu electrònic]
1.How fins on vol cobrir de diàmetre?
2.How alta que la torre?
3.Where ets?
I li donarem un assessorament més professional.
Sobre Nosaltres
FMUSER.ORG és una empresa d’integració de sistemes centrada en equips de transmissió i transmissió de vídeo sense fil de radiofreqüència / estudi i processament de dades. Oferim tot, des de l'assessorament i la consultoria a través de la integració de bastidors fins a la instal·lació, la posada en servei i la formació.
Oferim transmissor FM, transmissor de televisió analògica, transmissor de televisió digital, transmissor UHF VHF, antenes, connectors de cable coaxial, STL, processament aeri, productes de difusió per a estudi, monitorització de senyals RF, codificadors RDS, processadors d’àudio i unitats de control de llocs remots, Productes IPTV, codificador / decodificador d’àudio / vídeo, dissenyats per satisfer les necessitats de grans xarxes de difusió internacionals i de petites estacions privades.
La nostra solució compta amb estació de ràdio FM / estació de televisió analògica / estació de televisió digital / equip d’estudi d’àudio i vídeo / enllaç de transmissor d’estudi / sistema de telemetría de transmissor / sistema de televisió d’hotel / transmissió en directe IPTV / transmissió en directe de transmissió / conferència de vídeo / sistema de difusió CATV.
Utilitzem productes de tecnologia avançada per a tots els sistemes, ja que sabem que l’alta fiabilitat i l’alt rendiment són tan importants per al sistema i la solució. Al mateix temps, hem d'assegurar-nos que el nostre sistema de productes té un preu molt raonable.
Tenim clients de radiodifusors públics i comercials, operadors de telecomunicacions i autoritats reguladores, i també oferim solucions i productes a molts centenars d’emissores locals, petites i comunitàries.
FMUSER.ORG porta exportant més de 15 anys i té clients a tot el món. Amb 13 anys d’experiència en aquest camp, comptem amb un equip professional per resoldre tot tipus de problemes del client. Ens dediquem a subministrar els preus extremadament raonables de productes i serveis professionals. Correu electrònic de contacte : [protegit per correu electrònic]
la nostra fàbrica

Tenim modernització de la fàbrica. Que són benvinguts a visitar la nostra fàbrica quan s'arriba a la Xina.

En l'actualitat, ja hi ha clients 1095 a tot el món van visitar la nostra oficina Guangzhou Tianhe. Si vostè ve a la Xina, que són benvinguts a visitar-nos.
a la Fira

Aquesta és la nostra participació en 2012 Global Sources Hong Kong Electronics Fair . Els clients de tot el món finalment tenir l'oportunitat de reunir-se.
On és Fmuser?
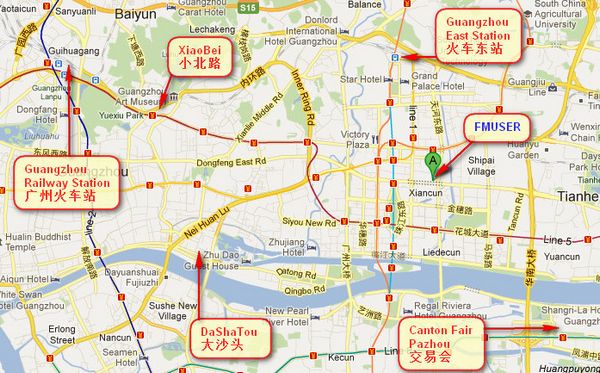
Podeu cercar aquests números " 23.127460034623816,113.33224654197693 "a google map, podreu trobar la nostra oficina fmuser.
FMUSER oficina de Guangzhou es troba al districte de Tianhe, que és el centre del Cantó . molt a prop fins al Fira de Canton , Estació de tren de Guangzhou, Xiaobei carretera i Dashatou , Només cal 10 minuts si pren TAXI . Benvinguts amics de tot el món a visitar i negociar.
Contacte: Blue Sky
Cel·lular: + 8618078869184
WhatsApp: + 8618078869184
Wechat: + 8618078869184
Adreça electrònica: [protegit per correu electrònic]
QQ: 727926717
Skype: sky198710021
Adreça: Sala de No.305 Huilan Edifici No.273 Huanpu carretera Guangzhou, Xina Codi postal: 510620
|
|
|
|
Anglès: Acceptem tots els pagaments, com PayPal, targeta de crèdit, Western Union, Alipay, Money Bookers, T / T, LC, DP, DA, OA, Payoneer, si teniu cap pregunta, poseu-vos en contacte amb mi [protegit per correu electrònic] o WhatsApp + 8618078869184
-
PayPal.  www.paypal.com www.paypal.com
Recomanem que utilitzi PayPal per comprar els nostres articles, el PayPal és una forma segura per comprar a Internet.
Cada pàgina de la nostra llista d'elements de fons a la part superior tenen un logotip de PayPal per pagar.
Targeta de crèdit.Si no té PayPal, però vostè ha targeta de crèdit, també pot fer clic al botó groc de PayPal per pagar amb la targeta de crèdit.
-------------------------------------------------- -------------------
Però si vostè no té una targeta de crèdit i no tenir un compte de PayPal o difícil va aconseguir un accout PayPal, pot utilitzar el següent:
Unió Occidental.  www.westernunion.com www.westernunion.com
Pagar per Western Union a mi:
Nom i cognoms: Yingfeng
Cognom / Cognom / Nom de família: Zhang
Nom complet: Yingfeng Zhang
País: Xina
Ciutat: Guangzhou
|
-------------------------------------------------- -------------------
T / T. pagar amb T / T (transferència bancària / transferència telegràfica / transferència bancària)
Primera informació bancària (COMPTE DE L'EMPRESA):
SWIFT BIC: BKCHHKHHXXX
Nom del banc: BANK OF CHINA (HONG KONG) LIMITED, HONG KONG
Adreça bancària: BANC DE LA TORRE DE XINA, 1 GARDEN ROAD, CENTRAL, HONG KONG
CÓDIG BANC: 012
Nom del compte: FMUSER INTERNATIONAL GROUP LIMITED
Núm de compte. : 012-676-2-007855-0
-------------------------------------------------- -------------------
Segona informació bancària (COMPTE DE L'EMPRESA):
Beneficiari: Fmuser International Group Inc.
Número de compte: 44050158090900000337
Banc del beneficiari: sucursal del Guangdong de China Construction Bank
Codi SWIFT: PCBCCNBJGDX
Adreça: carretera NO.553 Tianhe, Guangzhou, Guangdong, districte de Tianhe, Xina
** Nota: quan transferiu diners al nostre compte bancari, NO escriviu res a l'àrea de comentaris, en cas contrari no podrem rebre el pagament a causa de la política governamental sobre comerç internacional.
|
|
|
|
* Aquest document s'enviarà a 1 2-dies de treball quan el pagament és clar.
* Enviarem a la seva adreça de PayPal. Si vostè vol canviar la direcció, si us plau, envieu la vostra direcció correcta i número de telèfon a la vostra adreça [protegit per correu electrònic]
* Si els paquets es troba per sota 2kg, ens enviaran a través de correu aeri, trigarà aproximadament 15-25days a la mà.
Si el paquet és més que 2kg, enviarem a través d'EMS, DHL, UPS, Fedex lliurament ràpid expressa, prendrà al voltant de 7 ~ 15days al seu costat.
Si el paquet de més de 100kg, anem a enviar per DHL o el noli aeri. Es durà a prop 3 ~ 7days al seu costat.
Tots els paquets són la forma xinesa de Guangzhou.
* El paquet s'enviarà com a "regal" i es descomptarà el mínim possible, perquè el comprador no hagi de pagar l'impost.
* Després de la nau, li enviarem un correu electrònic i li donarà el nombre de seguiment.
|
|
|
Per a la garantia.
Poseu-vos en contacte amb nosaltres --- >> Envieu-nos l'article --- >> Rebeu i envieu un altre substitut.
Nom: Liu xiaoxia
Direcció: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou, Xina.
Postal: 510620
Telèfon: + 8618078869184
Si us plau, torni a aquesta adreça i escriure el seu PayPal, nom, adreça problema a la nota: |
|
El nostre altre producte:













